How We Think About Interruption Handling in Mira
Why reliable interruption handling in voice AI requires more than VAD and audio buffer clearing
When we designed Mira, a telephonic AI health assistant that places and receives real phone calls, interruption handling was treated as a first-class architectural concern, not an afterthought. A health conversation is not a chatbot exchange. The person on the other end is often anxious, sometimes mid-thought, frequently talking over the assistant. If the agent cannot handle that gracefully, the interaction breaks down at the worst possible moment.
Most discussions of voice AI interruption stop at two mechanisms: detecting when the user speaks, and clearing audio the user never heard. Both are real and necessary. But we reasoned through two further layers (context pollution and KV cache invalidation) that have an outsized impact on conversation quality, latency, and cost at scale. This post walks through all four layers, and explains the mark-based playback tracking we built for Mira that addresses them together.
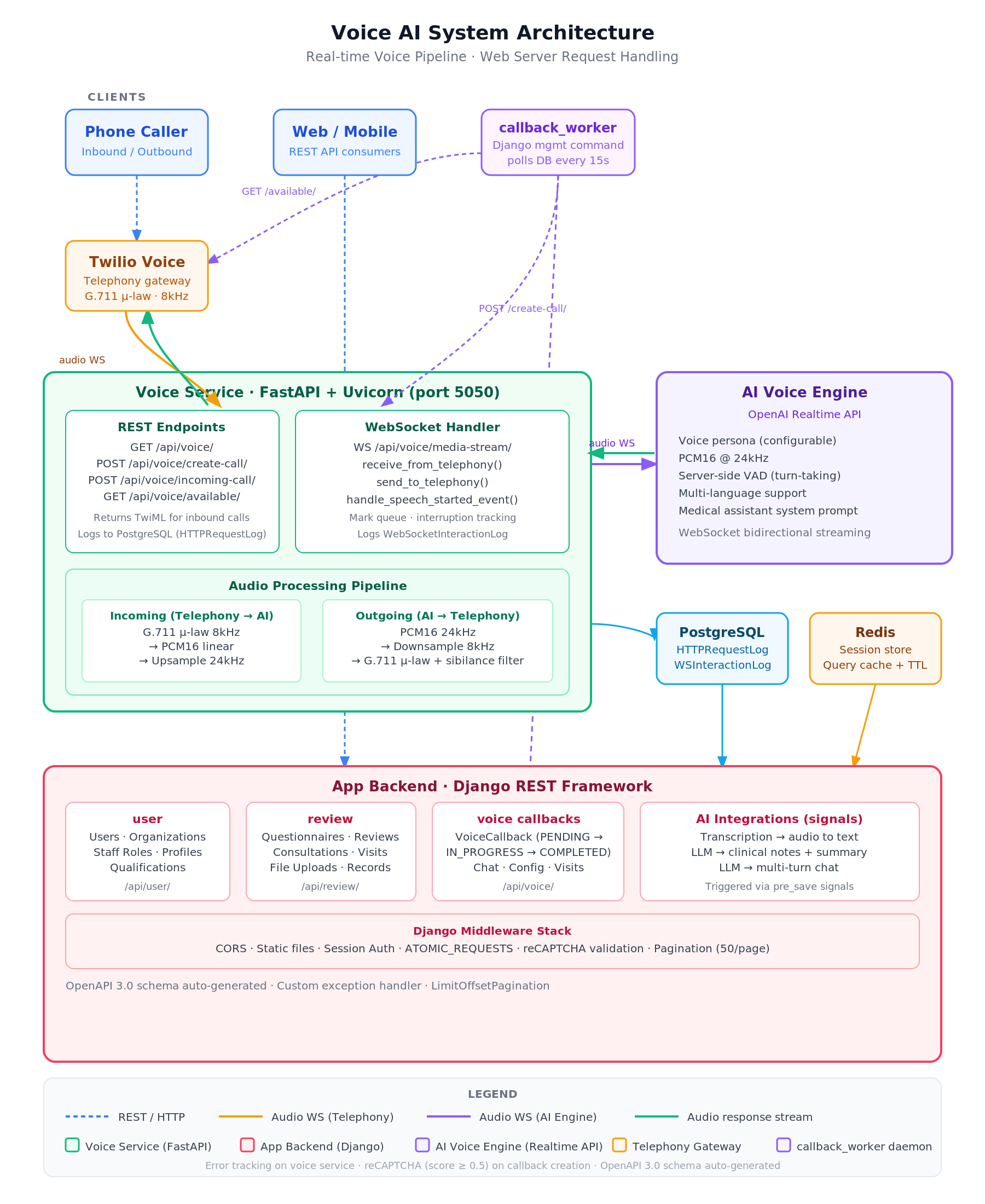
The diagram below provides a reference view of Bharosa’s full system architecture, covering the Mira voice service, telephony bridge, AI engine, and backend- for context as we walk through each layer of interruption handling.
The Foundation: VAD and Audio Clearance
Voice Activity Detection is where every voice AI system starts. The question it answers is: has the user started speaking?
The OpenAI Realtime API (which Mira runs on) offers three modes. Standard server VAD uses audio energy and silence thresholds. Three knobs are exposed: detection sensitivity, prefix padding (how much audio before the detection boundary to include), and silence duration (how long to wait before declaring a turn complete). Semantic VAD goes further, using the model’s understanding of meaning to decide when a thought is finished, rather than relying purely on silence. Push-to-talk disables VAD entirely and hands control to the application layer.
For Mira’s use case (live phone calls where 200ms of dead air already feels broken), we use server VAD with tuned parameters. silence_duration_ms is set tighter than the platform default, and prefix_padding_ms is wide enough to capture the opening consonant of a new utterance. These values were calibrated against real calls.
The companion mechanism is audio clearance. When a user interrupts, the model is generating audio faster than realtime (it produces ahead of playback), which means there are frames already queued in the telephony bridge that haven’t reached the caller yet. Without clearing that buffer explicitly, the caller hears old assistant speech after they’ve already begun talking. A clear event to Twilio drops the queued frames and prevents that overlap.
The Frame: Three Ledgers That Must Stay Aligned
A useful way to think about interruption is to separate three objects that look like one:
| Ledger | What it contains | Survives interruption? |
|---|---|---|
| Generated output | Everything the model produced, including audio and transcript, including content generated after playback began | Only up to the playback boundary |
| Played audio | What the caller actually heard before the interruption | Yes, source of truth |
| Committed state | Backend actions already confirmed: bookings, records, API responses | Yes, if truly confirmed |
In an uninterrupted turn, these three align cleanly. An interruption splits them. The model may have generated twenty seconds of response while the caller heard five. An action may have been described before it was actually confirmed. The gap between these ledgers is where the real engineering work lives.
Problem 1: Context Pollution
When Mira builds the prompt for the next model turn, it is constructing a representation of the conversation so far. The question that determines whether the system is trustworthy is: what actually enters that history after an interrupted turn?
If the full generated output enters context (regardless of how much the caller heard), the model’s next response is reasoned from a premise the caller does not share. It will treat an unacknowledged statement as acknowledged. It will not re-explain something the caller never heard. In a health context, this is not a minor UX imperfection. It can mean the model believes it delivered clinical information that never reached the patient.
The particularly sharp case is uncommitted state. If the assistant says “Your appointment is confirmed for Thursday” mid-interruption (before the backend confirmation has returned), and that statement enters the next context, the model and the backend are operating on different realities. The model believes the booking exists. It does not.
The OpenAI Realtime API provides a primitive for this: conversation.item.truncate. It takes a playback cutoff time and removes the server-side transcript for all content past that point: the output the caller did not hear is removed from the conversation context. When applied correctly, the model’s next turn begins from an accurate shared record. Applying it correctly requires knowing the playback boundary precisely, and sending events in the right sequence, covered in the architecture section below.
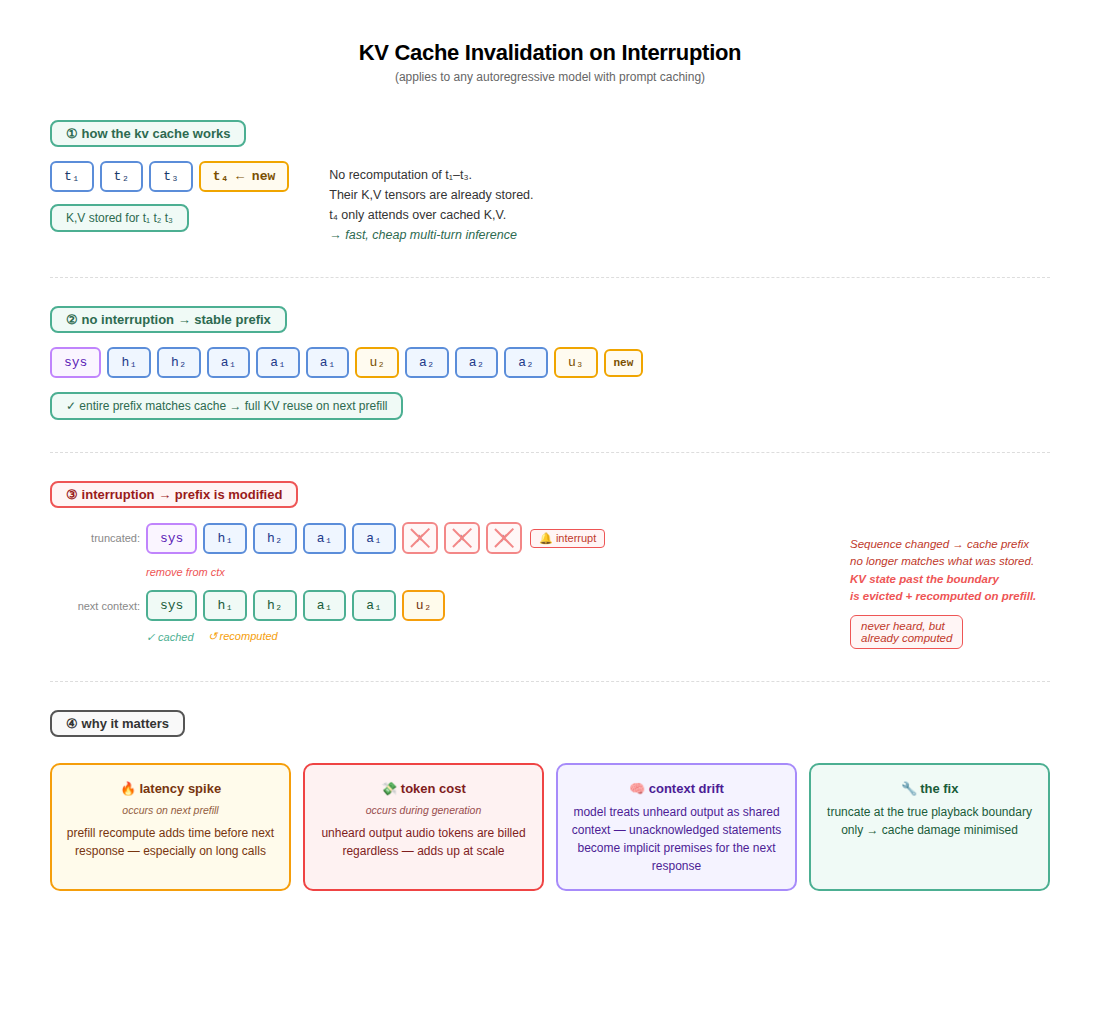
Problem 2: KV Cache Invalidation
Mira runs on the OpenAI Realtime API, which applies automatic prompt caching server-side. No explicit opt-in is required: when consecutive turns within a session share a stable prefix (the system instructions followed by accumulated conversation history), the model reuses previously computed state for that prefix rather than reprocessing it from scratch. When a cache hit occurs, OpenAI’s documentation quotes up to 90% reduction in input token cost and up to 80% reduction in response latency for the cached portion.
To understand why interruptions interact with this, it helps to have a mental model of how the model’s memory works internally.
A Brief Primer on KV Cache
Realtime speech-to-speech models, like those powering the OpenAI Realtime API, are still autoregressive at the token level: they generate one token at a time. For each new token, the model attends over all previous tokens in context to compute a contextually-aware output. Naively, this requires reprocessing all prior tokens on every step.
The KV cache eliminates this work. For every token already processed, the model stores two intermediate tensors (a key (K) and a value (V)) at every layer of the network. When the next token is generated, these stored values are retrieved rather than recomputed. The K and V tensors represent, in compressed form, how each previous token should influence subsequent ones. The cache is what makes multi-turn conversations with large models fast enough to be useful in production.
Prompt caching extends this across turns: if the beginning of the conversation context matches what was recently processed, the KV state for that prefix is reused rather than recomputed. The longer and more stable the shared prefix, the greater the benefit.
For Mira, the structure that benefits from prompt caching within a session is:
The prompt caching benefit for Mira is within a session: as the conversation accumulates, each new turn reuses the KV state already computed for earlier turns, keeping response latency low and consistent as the conversation grows.
How Interruptions Damage This
An interruption has two effects on the prompt cache, at two different timescales.
During active generation. When an interruption fires, the model may have already produced audio that hasn’t reached the caller. Those tokens were generated and are billed as output because the compute to produce them has already run. The earlier in a response an interruption fires, the fewer billed-but-unheard tokens accumulate. This is a direct output token cost: generated audio tokens are billed regardless of what happens to the response afterward.
Across turns. This is the more consequential effect. When conversation.item.truncate modifies the conversation history (removing the unheard portion of the assistant’s turn), the token sequence of the context changes. The prefix that was cached after the previous turn no longer matches the modified history. The result can be reduced prompt cache reuse on the next turn: instead of reusing as much of the KV state accumulated over the conversation, the model may need to recompute more during the prefill phase.
Our Solution: Checkpoint-based Interruption handling
Understanding these four layers (VAD, audio clearance, context pollution, and prompt cache invalidation) shaped the architecture we built. The approach we use in Mira treats outbound assistant audio as a timeline tracked through Twilio marks and media timestamps.
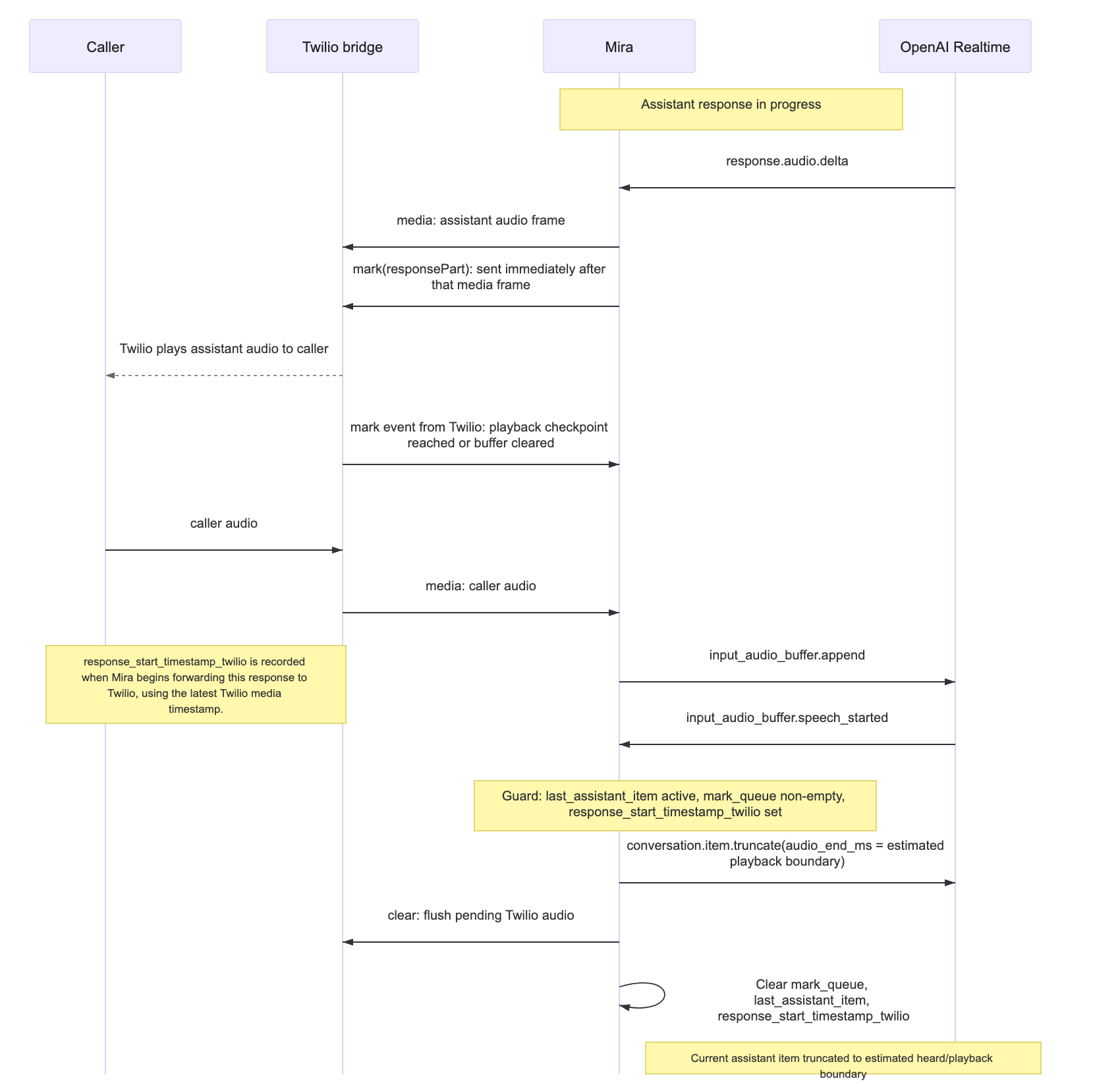
What a Mark Is
The approach centres on mark events. Every time an audio chunk is forwarded to Twilio, Mira immediately sends a mark(responsePart) event and appends it to a local mark queue. Twilio sends mark events back when playback reaches those checkpoints, and can also send them when buffered audio is cleared. Mira drains the queue as those mark events arrive. This creates a practical guard: the interruption correction only executes when the mark queue is non-empty and an active assistant item is in progress.
Alongside the mark queue, Mira tracks three values relevant to the current response:
• response_start_timestamp_twilio: the Twilio media timestamp recorded when Mira starts forwarding the current response to Twilio.
• latest_media_timestamp: the most recent Twilio media timestamp seen on any inbound frame. Updated continuously; not reset between responses.
• last_assistant_item: the item ID of the response currently being spoken.
When an interruption fires, these values answer the only question all the downstream work depends on: how many milliseconds of the current response likely reached playback?
elapsed_time = latest_media_timestamp − response_start_timestamp_twilioThis elapsed time becomes audio_end_ms passed to OpenAI. It is an approximation (network latency between Twilio and the physical handset means the true playback position at the caller’s ear is slightly ahead), but it is a consistent, directionally accurate estimate.
The Three-Step Correction
When the model detects caller speech and the guard conditions are met (mark queue non-empty, assistant item active), Mira executes a three-step correction.
Each step has a specific role:
1. Truncate the current assistant item. conversation.item.truncate with audio_end_ms set to the elapsed time modifies the current assistant item in OpenAI's conversation state, cutting the audio and removing the transcript for the unheard portion. This is a targeted operation on the active item; it does not rebuild or globally rewind the session. The model’s next response is generated from context that no longer includes what was never heard, which is the fix for context pollution.
2. Clear the Twilio buffer. A clear event drops queued audio frames at the bridge, preventing stale assistant audio from reaching the caller after they have interrupted.
3. Clear response-scoped local state. mark_queue, last_assistant_item, and response_start_timestamp_twilio are reset. latest_media_timestamp is not reset; it continues tracking Twilio's media timeline continuously and will anchor the next response’s start timestamp when audio begins flowing again.
Because the correction targets only the current assistant item rather than discarding the full turn, everything committed before the playback boundary is preserved intact. If the caller interrupted after the assistant described a symptom but before it suggested a next step, the symptom description remains in the session and the suggestion does not. The session continues from that accurate boundary, and the prompt cache advantage built up to that point is preserved as far as the truncation allows.
What This Means in Production
Three properties emerge from this architecture that we track as product-level signals alongside the usual quality metrics.
Conversation coherence after interruption. Mira does not act on things it said that the caller never heard, and does not omit things said before the interruption. This is a direct consequence of the current assistant item being truncated at the playback boundary rather than the full turn being discarded or retained wholesale.
Latency stability over long calls. Because context is corrected at the playback boundary rather than broadly discarded, the conversation’s earlier history remains as stable as possible across turns. That gives prompt caching the best chance to keep response latency low as the call progresses.
Cost per session at scale. Interruptions generate billed output tokens that go unheard, and each interruption that modifies context can reduce cache reuse on the subsequent turn. Playback-boundary correction limits both effects, minimising unheard output tokens and keeping the context modification as small as possible to maximise cache reuse. For a health assistant handling many calls per day, the difference between precise and imprecise interruption handling shows up in cost.
The Underlying Principle
Voice AI architecture is, at its core, a state-management problem with a Realtime audio interface on top.
The model generates good language. The hard part is ensuring the state it reasons from is accurate: that what is in context actually reflects the conversation that occurred, that prompt cache behaviour is considered alongside model quality, and that interruption is handled in a way that keeps all three ledgers aligned.
The mark-based approach is how we operationalise that principle in Mira. It gives us an auditable estimated boundary between committed and uncommitted content on every interrupted turn. Everything downstream (the next context window, the cache strategy, the patient-facing conversation quality) is built from that boundary.