Teaching AI to Remember: Building Persistent Memory with Mem0, pgvector, and Neo4j
A practical walkthrough of a durable, hybrid memory layer for LLM-backed products — and why the architecture matters beyond one domain.
The problem: LLMs have no memory
Large language models are brilliant in the moment and amnesiac between moments. Every request to a model is stateless: the weights don't change, nothing is written back, and the only "memory" the model has is whatever tokens you hand it in the prompt. Close the tab, start a new session, and the model has no idea it has ever spoken to you before.
For many applications — a one-shot coding helper, a translation tool, a summarizer — this is fine. The task is self-contained and the context window is big enough to hold everything the model needs.
The moment an application becomes relational — when it's expected to know who you are, what you care about, what you said last week, and how that relates to what you're saying now — the stateless model becomes a liability. Shoving the entire history into the context is expensive, slow, and eventually impossible. Retrieval-augmented generation (RAG) over a document store helps, but RAG is optimized for looking things up in a corpus someone else wrote. It isn't designed for the messy, evolving, sometimes-contradictory stream of facts that make up a person.
That gap is where persistent memory lives. A persistent memory layer watches conversations (and other signals), decides what is worth remembering, stores those facts in a form that can be searched later, reconciles them as they change, and injects the relevant ones back into future prompts. Done well, it's the difference between an assistant that greets you like a stranger every morning and one that actually knows you.
This post walks through how we built that layer using Mem0, pgvector, Neo4j, and a thin HTTP contract between our Django application and a dedicated memory service. We'll motivate the need, explain the architecture, and close with the engineering concerns that separate a memory system you demo from one you run in production.
Why memory matters more when the user relies on you
The product context for this work is a platform that supports people with intellectual and developmental disabilities (I/DD), along with their caregivers and guardians. I won't go deep into product specifics, but one thing is worth stating plainly because it shapes every architectural decision downstream: for this audience, "the system forgot" is not a minor UX paper cut.
A self-advocate may rely on the assistant to remember that a particular phrase is upsetting, that mornings are harder than evenings, that one support worker is trusted and another is unfamiliar, that a specific routine is the reason the day didn't fall apart yesterday. Caregivers rely on it to surface continuity they themselves can't always hold — shifts rotate, memories blur, and the person in front of them may not be able to re-explain their own preferences on demand.
A stateless chatbot in this context isn't just unhelpful. It's actively disorienting. Every interaction that starts from zero re-imposes the cognitive load the tool was supposed to reduce. So "remember things across sessions" stops being a nice-to-have feature and becomes a core correctness property of the system. That framing — memory as correctness, not convenience — is what made a purpose-built memory layer non-negotiable for us, and it's why we invested in something richer than a conversation log.
If you're building anything with similar properties — a therapist's co-pilot, a tutor, an onboarding assistant, a longitudinal health tool — the same pressure applies. The moment your users are not in a position to restate context on demand, your memory layer becomes part of your product's safety surface, not just its intelligence surface.
What a memory layer actually needs to do
Before architecture, requirements. A persistent memory layer for an LLM application has to solve at least five problems:
- Extract what matters. Not everything a user says is worth remembering. "What time is it?" is noise. "I don't like being touched on the shoulder" is a durable preference. Something has to triage.
- Store durably and searchably. Memories need a home that survives deployments, can be queried by meaning (not just by keyword), and can scale past anything that fits in RAM.
- Reconcile over time. People change their minds. Preferences evolve. Contradictions appear. A good memory system updates and retires old facts instead of letting a lake of stale statements drown out the current truth.
- Retrieve the relevant subset on demand. At prompt time, you have a few hundred tokens of budget for memory. You have to pick the right handful out of thousands.
- Stay out of the way when it fails. Memory is helpful, but a memory outage cannot take the product down. If the memory service is having a bad day, the assistant should degrade to a less-personalized version of itself, not a 500 page.
Mem0 covers (1) through (4) as a library. The surrounding system has to solve (5), and it has to choose how to wire (1)–(4) into its own data model.
Anatomy of the memory service
Our memory service is a small FastAPI process sitting next to our main Django application. It wraps Mem0 and exposes a narrow HTTP contract — add, search, get, update, delete, and a history endpoint — behind an API key. The Django side never touches vectors, graphs, or embedding models directly; it calls HTTP and gets text back.
Under the hood, the service composes four subsystems:
- An extraction LLM that reads raw conversation turns and produces candidate facts.
- An embedding model that turns facts into dense vectors.
- A vector store (pgvector) for semantic retrieval.
- A graph store (Neo4j) for entity-and-relationship retrieval.
- A history database (SQLite) that logs every write for auditability.
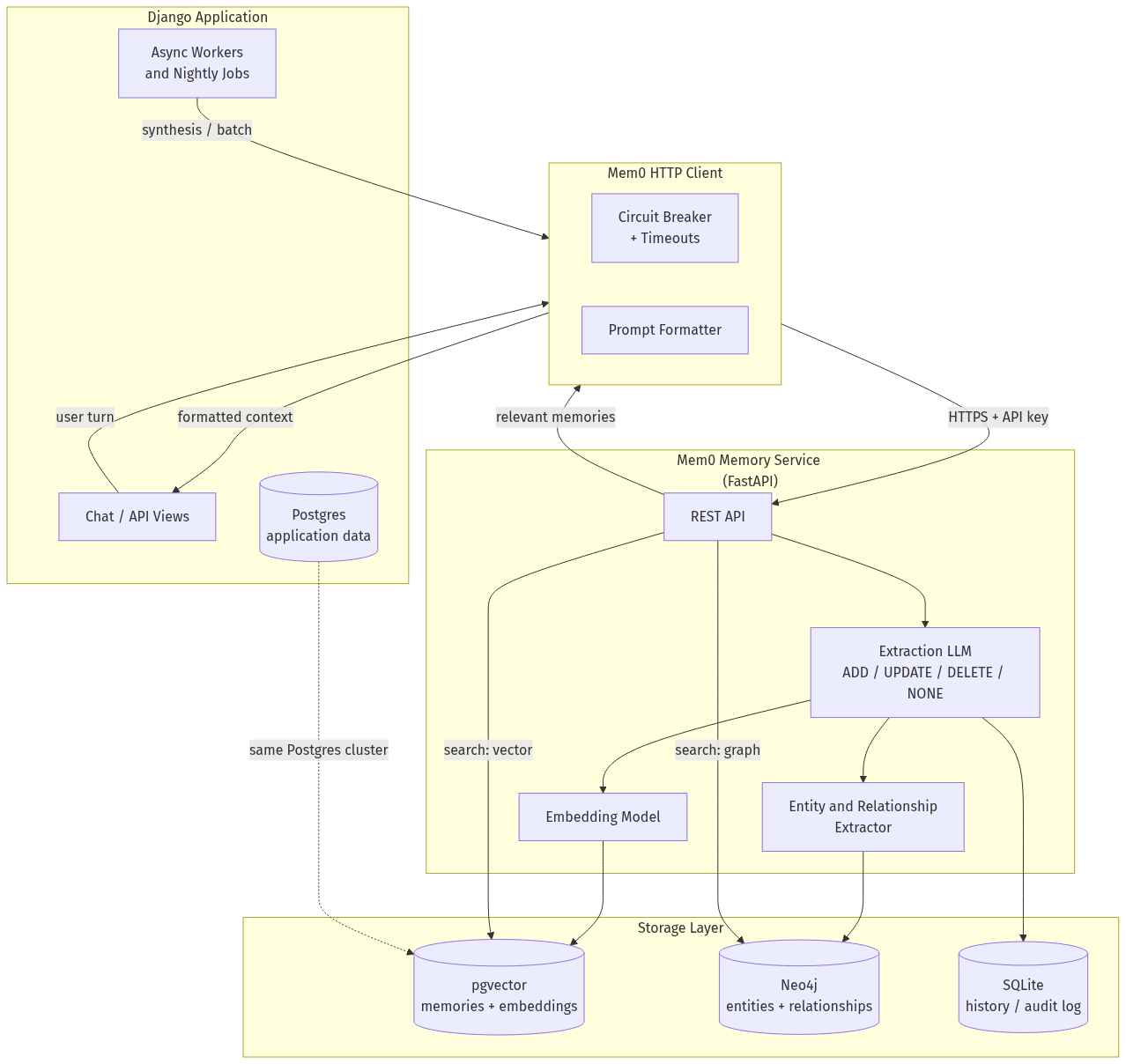
Two structural points are worth calling out before we zoom in.
First, the memory service is a service, not a library inside Django. That's a deliberate choice. It lets us scale and restart it independently, run it against a different model pool, and — critically — treat it as optional. The Django side is hardened against the service being slow, absent, or wrong.
Second, pgvector runs inside the same Postgres cluster as our application data. We get transactional durability, familiar ops, and the ability to reason about memory alongside the rest of our domain model without shipping vectors to a separate managed service. Neo4j is the one piece of net-new infrastructure we took on, because no existing store in our stack did property-graph traversal well.
The vector layer: pgvector and HNSW
The vector store is where "semantic search" happens. At write time, each memory fact is embedded into a 1536-dimensional vector (the current default for the OpenAI text-embedding-3-small family; 3072 for -large). At read time, the incoming query is embedded the same way, and the store returns the memories whose vectors sit closest to the query in that high-dimensional space.
Two design choices matter here.
The first is pgvector over a dedicated vector database. Qdrant, Pinecone, Chroma, FAISS, and MongoDB Atlas are all supported by Mem0 and all reasonable choices; we picked pgvector because it collapses what would otherwise be a separate operational surface into infrastructure we already run. Vector search becomes just another index in Postgres. Backups, replicas, role-based access, and observability all follow our existing playbook. When the memory model and the application model can live in the same database, a lot of "cross-store consistency" problems simply don't come up.
The second is HNSW indexing. Vector search without an approximate index is an O(N) scan of every stored vector, which is fine for thousands of memories and catastrophic for millions. HNSW (Hierarchical Navigable Small Worlds) is a graph-based approximate-nearest-neighbor index that gives you sub-linear search with a knob for the speed-versus-recall trade-off. pgvector supports both HNSW and DiskANN; we default to HNSW because its build-time cost amortizes well over our write patterns, and because recall at the top-k sizes we actually care about (5–10) is excellent in practice.
Semantic search alone gets you a surprising distance. "What does the user find calming?" will surface memories about quiet evenings and specific music even if none of them contain the word "calming." That's the whole value proposition of embeddings: meaning, not keywords.
But semantic search also has a well-known failure mode. It can confidently return memories that are topically similar but relationally wrong — facts about the user's sister when you asked about the user's mother, facts about a past caregiver when you asked about the current one. That's where the graph comes in.
The graph layer: entities and relationships
The graph store holds a different representation of the same memories. Where the vector store treats each fact as an opaque point in embedding space, the graph extracts the entities inside the fact (people, places, things, concepts) and the relationships between them, and stores those as nodes and edges in Neo4j.
At write time, a second extraction pass runs over each new memory. If the memory is "Priya is Maya's primary caregiver on weekdays," the graph sees three entities (Priya, Maya, weekdays) and relationships (is_caregiver_for(Priya, Maya), schedule(Priya, weekdays)) rather than a dense vector. A similarity threshold (default 0.7) controls how aggressively the extractor merges a newly-seen entity with an existing one — high enough to avoid creating a new Priya node every time someone types her name, low enough to distinguish two different Priyas.
At read time, the graph gets queried alongside the vector store and the results are merged. This dual retrieval is the single biggest architectural reason we chose Mem0 over rolling our own embedding-only store. The two retrievers fail differently:
- The vector store is excellent at "memories about this topic."
- The graph is excellent at "memories about this entity and the entities it's connected to."
A good retriever for a personalized assistant needs both. When a user asks about "my morning routine," semantic search finds the ones about waking up, breakfast, and medication timing. But the graph is what ensures we surface the specific support worker who is actually on shift this morning, not a worker who is semantically similar in the embedding space but structurally wrong in the real world.
There's a configuration knob for disabling the graph layer entirely (GRAPH_STORE_PROVIDER=none), which is useful for small deployments where the operational cost of Neo4j outweighs the retrieval quality gain. For anything user-facing and long-running, we strongly recommend leaving it on.
The write path: ADD, UPDATE, DELETE, NONE
Here's where Mem0 does something subtler than most memory systems.
When a new conversation turn arrives, the service doesn't just embed it and shove it into the vector store. It runs the turn through an extraction LLM that produces candidate facts, and then — for each candidate — it decides one of four things:
- ADD — this is a new fact, store it.
- UPDATE — this contradicts or refines an existing fact; modify the existing entry rather than creating a duplicate.
- DELETE — this supersedes an existing fact in a way that makes the old one wrong; remove it.
- NONE — this isn't worth remembering, drop it.
That four-way decision is doing a lot of work. It's the mechanism that prevents the memory store from becoming a landfill. Without it, every "I like tea" followed later by "actually I've switched to coffee" leaves you with two equally-ranked, contradictory memories and no principled way to pick between them at retrieval time. With it, the store converges toward a coherent current picture of the user.
The history database captures every one of these decisions — the old value, the new value, the operation, the timestamp. That audit log matters for debuggability (why did the model "know" this yesterday but not today?), for compliance (we can show exactly what we stored about a user and when), and for trust (memories aren't a black box; they can be inspected and reverted).
The read path: scoped, bounded, and graceful
At prompt time, the flow is simpler but the constraints are tighter.
When a user sends a message, the application embeds the message as a query and asks the memory service for the most relevant facts, scoped to this user, optionally narrowed by an agent_id (which subsystem the memory belongs to) and a run_id (a particular workflow or session). The response is a ranked list of short memory strings. The client formats them — typically as a bulleted "Relevant long-term memories" block — and injects them into the system prompt before the model generates its response.
Three details make this practical rather than theoretical.
Identity scoping. Every memory is written with at least one of user_id, agent_id, or run_id, and every search filters by the same fields. That's how the store stays partitioned: user A's memories never leak into user B's prompts, memories from one subsystem don't pollute another, and short-lived workflow memories can be segregated from durable user preferences. The application controls the scope; Mem0 enforces it.
Bounded payloads. Retrieved memories are capped (we use five items by default), each memory string is clipped to a few hundred characters, and the whole block is inserted into the prompt as a clearly-delimited section. This prevents the retrieval layer from blowing out the context window or, worse, letting a single very long memory dominate the model's attention.
Graceful degradation. Memory retrieval is wrapped in a circuit breaker. If the memory service is slow or failing, the client short-circuits after a configured threshold, the application logs a warning, and the model generates its response with no memory block at all. The user gets a less-personalized answer; they do not get an error. For a product where the memory service is a dependency of nearly every interaction, this property is non-negotiable.
There's also a user-facing opt-out — an "incognito" mode that skips both the write and the read paths. This matters for a population that is sometimes asked to consent to things they haven't fully processed. Memory can be turned off per conversation without turning off the product.
Sitting next to Django and Postgres
One of the more interesting side effects of this architecture is how cleanly it composes with a conventional Django/Postgres stack.
The Django side never needs to know what an embedding is. Its responsibility ends at calling the memory client with a small dict: some messages, a user identifier, a scope, and optionally some metadata. Everything below that — the extraction LLM, the embedding, the vector insert, the graph update, the history log — happens behind the HTTP boundary.
Meanwhile, because pgvector lives in the same Postgres cluster as the rest of our application data, we can reason about memories with the same operational tools we use for everything else. Point-in-time recovery covers memories. Replicas cover memories. Row-level security policies, if we want them, cover memories. Nothing about the memory layer requires standing up a separate observability or backup story. Neo4j is the exception — it has its own operational surface — but it's a well-understood one, and it's the piece of the system pulling its weight in retrieval quality.
The write path ends up happening in two places: synchronously, after an assistant response is generated (so the most recent exchange contributes to long-term memory), and in batch, during a nightly job that distills longer-running patterns — emotional trends, recurring topics, and the kind of slow-moving insights that only become visible across many conversations. The two write paths use different agent_ids so their contributions can be audited and tuned separately.
What this architecture buys
Stepping back from the specifics, the design choices compound:
- Dual retrieval (vector + graph) delivers higher retrieval precision than either store alone, because the failure modes are different.
- LLM-mediated writes with ADD/UPDATE/DELETE/NONE keep the memory store converging on current truth instead of accumulating contradictions.
- A dedicated service behind a narrow HTTP contract lets the application treat memory as an optional capability and hardens the product against memory outages.
- pgvector co-located with application Postgres eliminates an entire operational surface without sacrificing retrieval quality at the scales most applications actually operate at.
- History-backed auditing turns memory from a black box into an inspectable, revertible system — which matters for debugging, for compliance, and for trust.
- Identity scoping (
user_id/agent_id/run_id) gives the application crisp control over who sees what, without requiring the memory layer to understand the application's domain model.
For a relational, long-running AI product — ours serves people with intellectual and developmental disabilities, but the pattern generalizes to any assistant that's expected to know its user — this architecture is the difference between a clever demo and a system that holds up in production. The LLM is still the bright, forgetful prodigy it has always been. The memory layer is what gives it a diary.